Dongwei Jiang
LLM agents, reasoning and self-improvement. Previously focused on speech
Currently Applied Scientist at Amazon. Previously master's student at JHU
Research Interest
Nowadays, I’m increasingly interested in the limits of LLMs themselves. Is autoregressive prediction really the best architecture? Do we truly need massive datasets during pretraining? How can we bridge the training-inference gap? If you’re also thinking about these problems, I’d love to chat!
Previously, I’ve worked extensively on agents, reasoning, and self-improvement:
Agents: I’ve worked on agentic RL and security agents that can autonomously identify and validate vulnerabilities.
Reasoning: In the realm of reasoning, I’ve worked on:
- Building general-purpose verifier through rationale extraction from unlabelled data to provide process supervision during reasoning [1] (mentioned in Lilian Weng's blog)
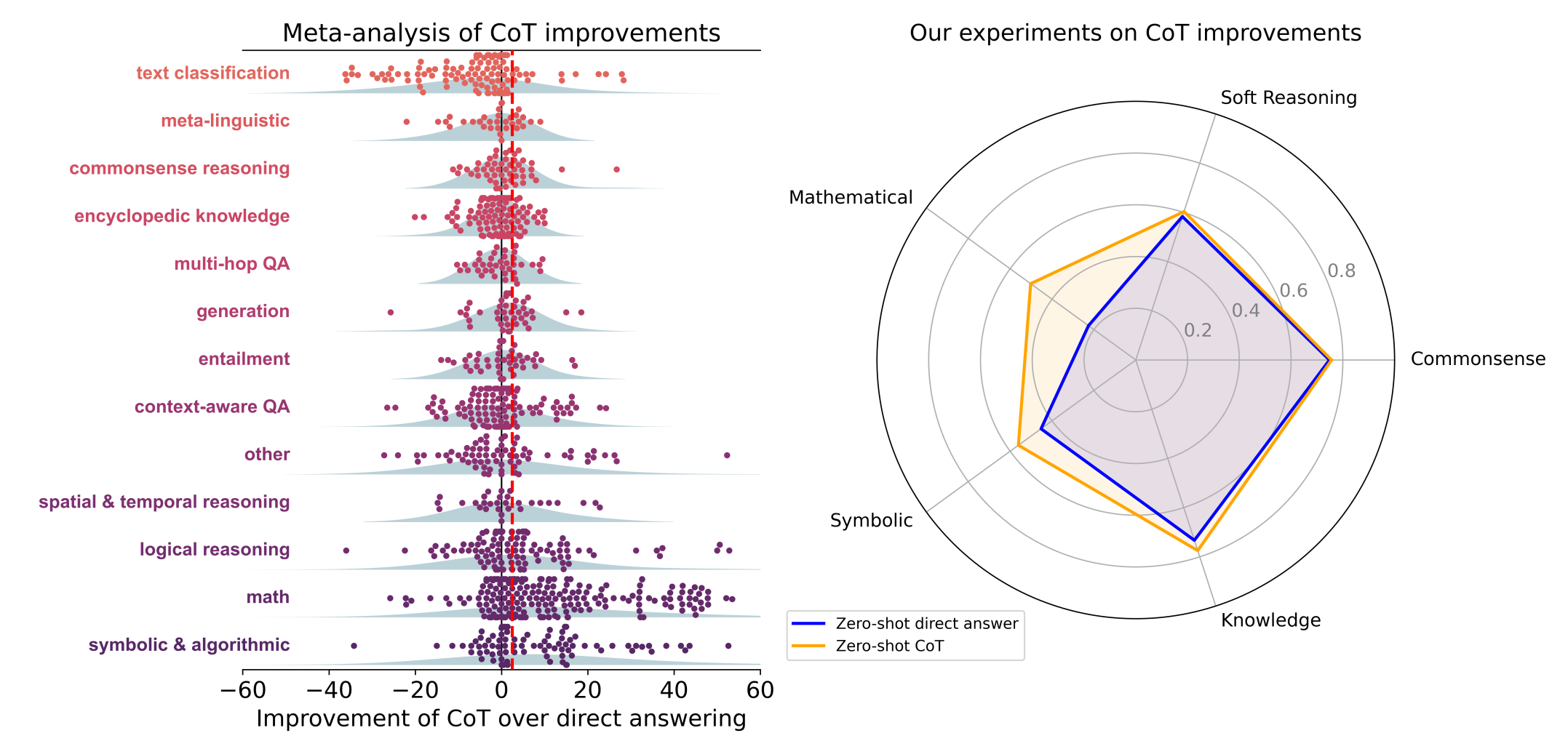
- Investigating the effectiveness of CoT prompting across 100+ papers and 20 datasets and discovering CoT benefits mainly math/symbolic reasoning tasks [2] (discussion with Jason Wei)
- Theorem proving and Logical reasoning that uses theorem prover Lean to help with the reasoning process [3]
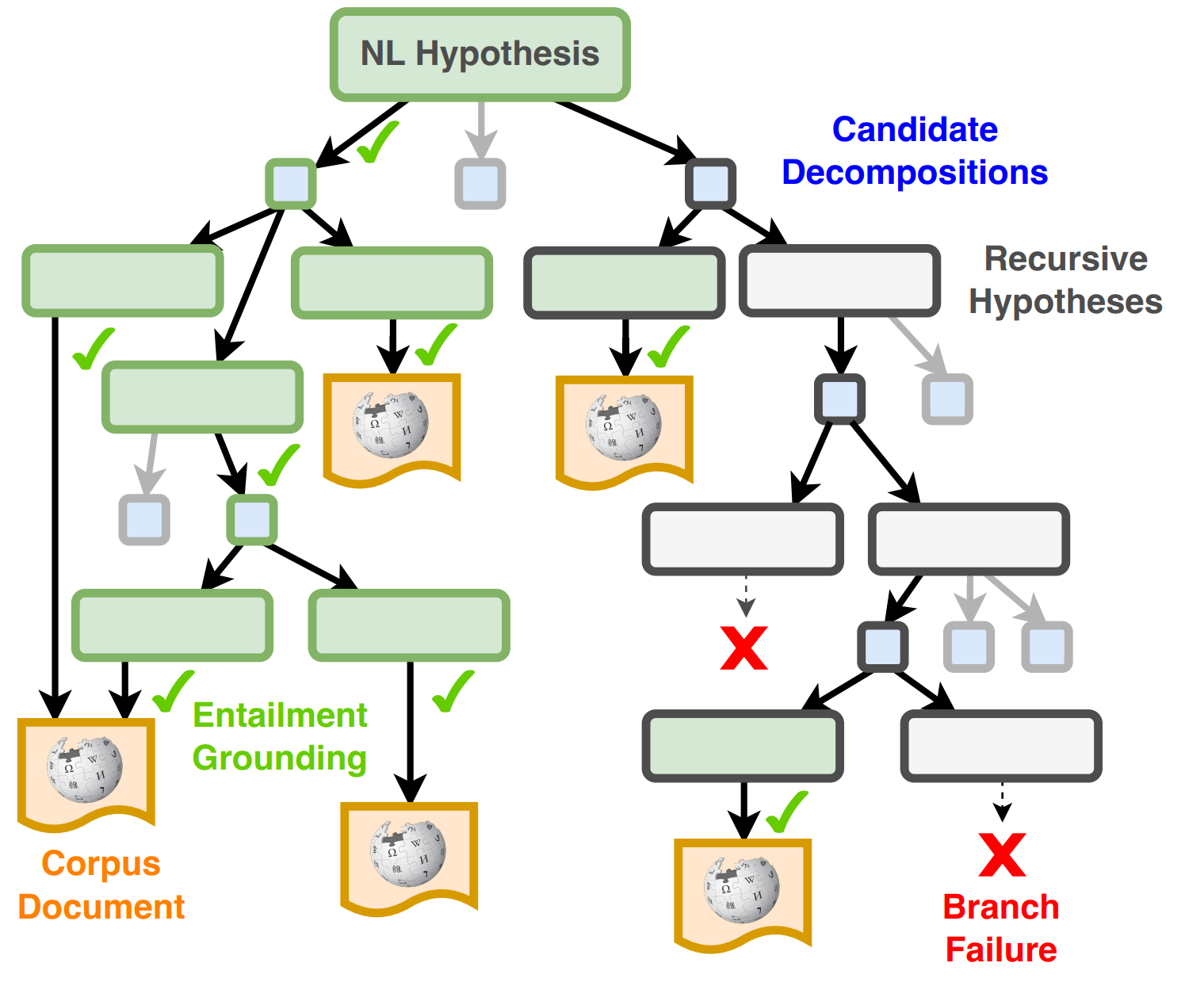
- Decompositional entailment that formulates a consistent and theoretically grounded approach to annotating decompositional entailment dataset [4]
Self-improvement: If we begin with the “end” (superintelligence/AGI) in mind, relying on human input won’t get us there. We need to teach models to interact with the environment and self-improve. Within this area, I’ve worked on:
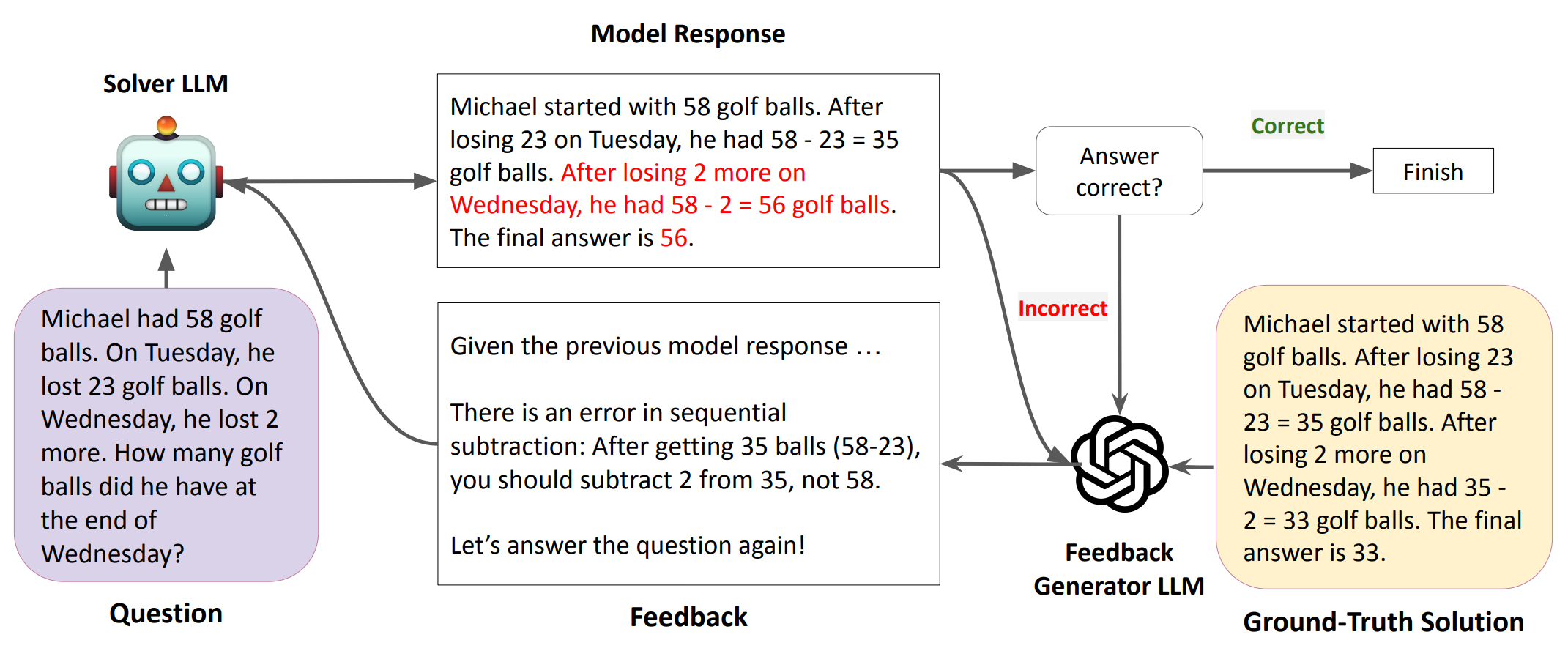
- Understanding the reason that prevents LLM from effective self-improvement [5]
- Probing the limits of self-improvement even with high-quality feedback [6]
News
| Dec, 2025 | Attending NeurIPS 2025 in San Diego. Come say hi! |
|---|---|
| Jul, 2025 | Attending ACL 2025 in Vienna. Come say hi! |
| May, 2025 | Paper Feedback Friction accepted to NeurIPS 2025! |
| Mar, 2025 | Paper RATIONALYST accepted to ACL 2025! Featured in Lilian Weng’s blog. |
| Jan, 2025 | Paper To CoT or Not to CoT accepted to ICLR 2025! |
| Jan, 2025 | Joined Amazon as Applied Scientist II, working on security agents and agentic RL. |
| Dec, 2024 | Paper SELF-[IN]CORRECT accepted to AAAI 2025! |
More About Me
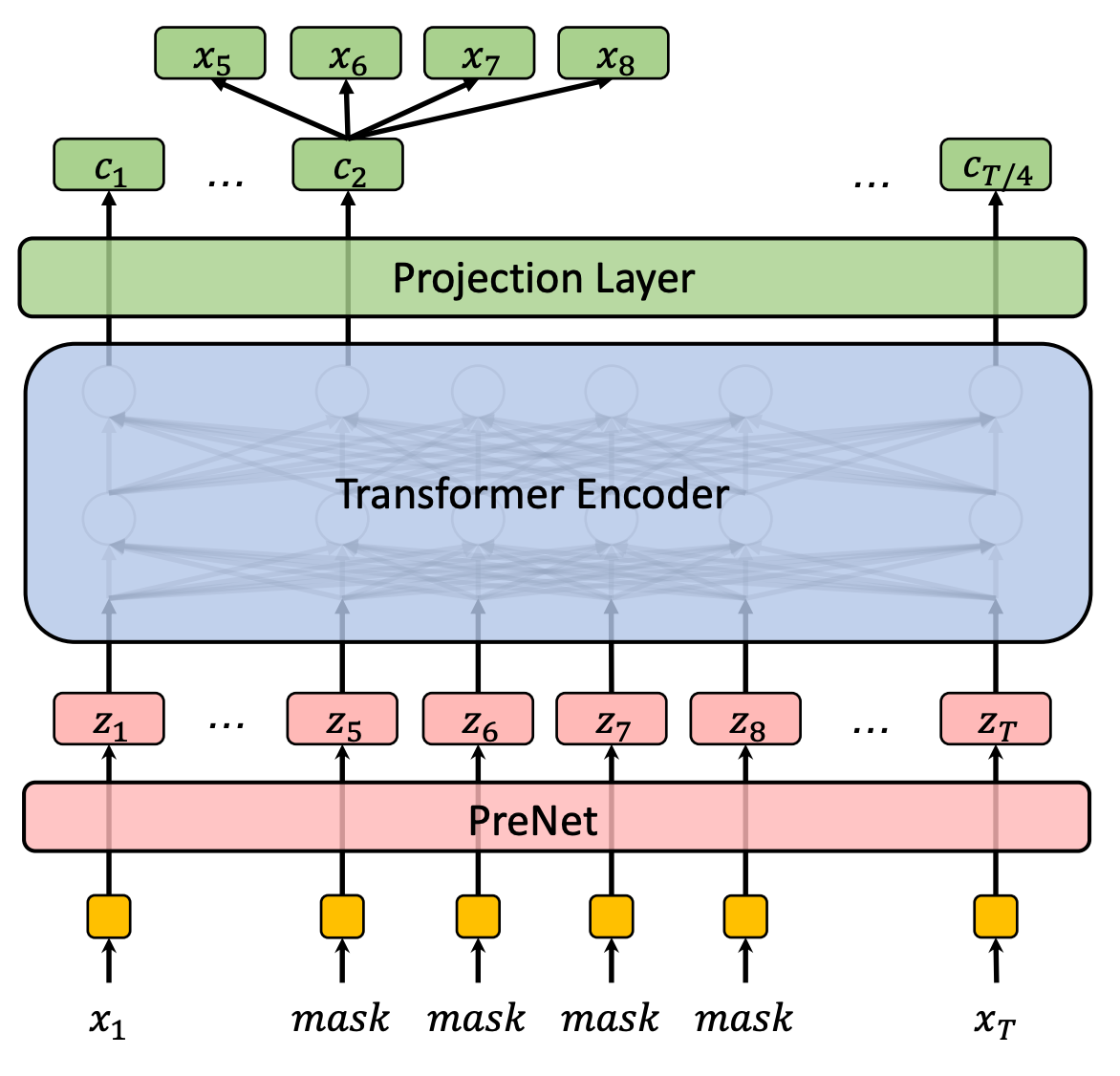
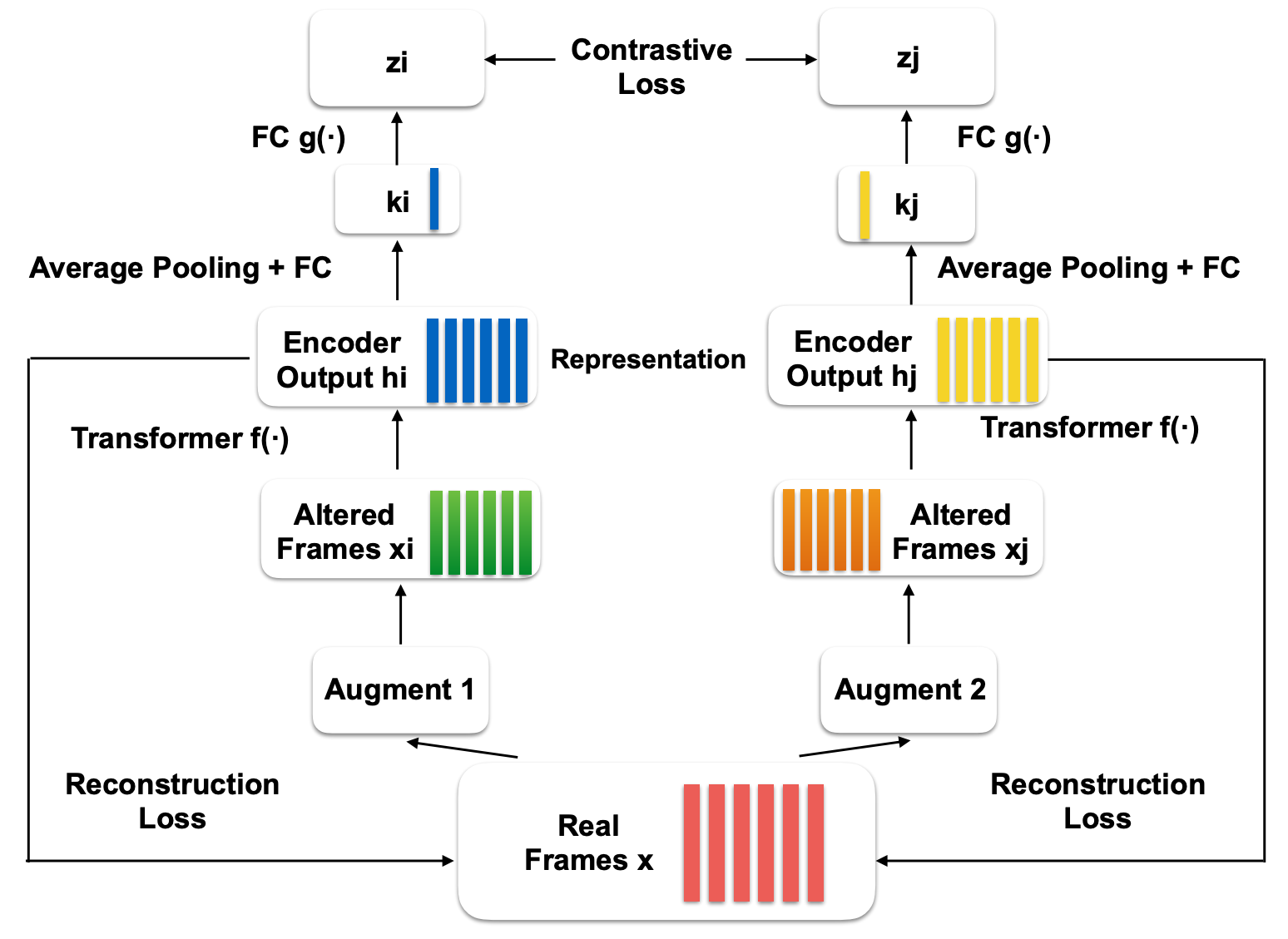
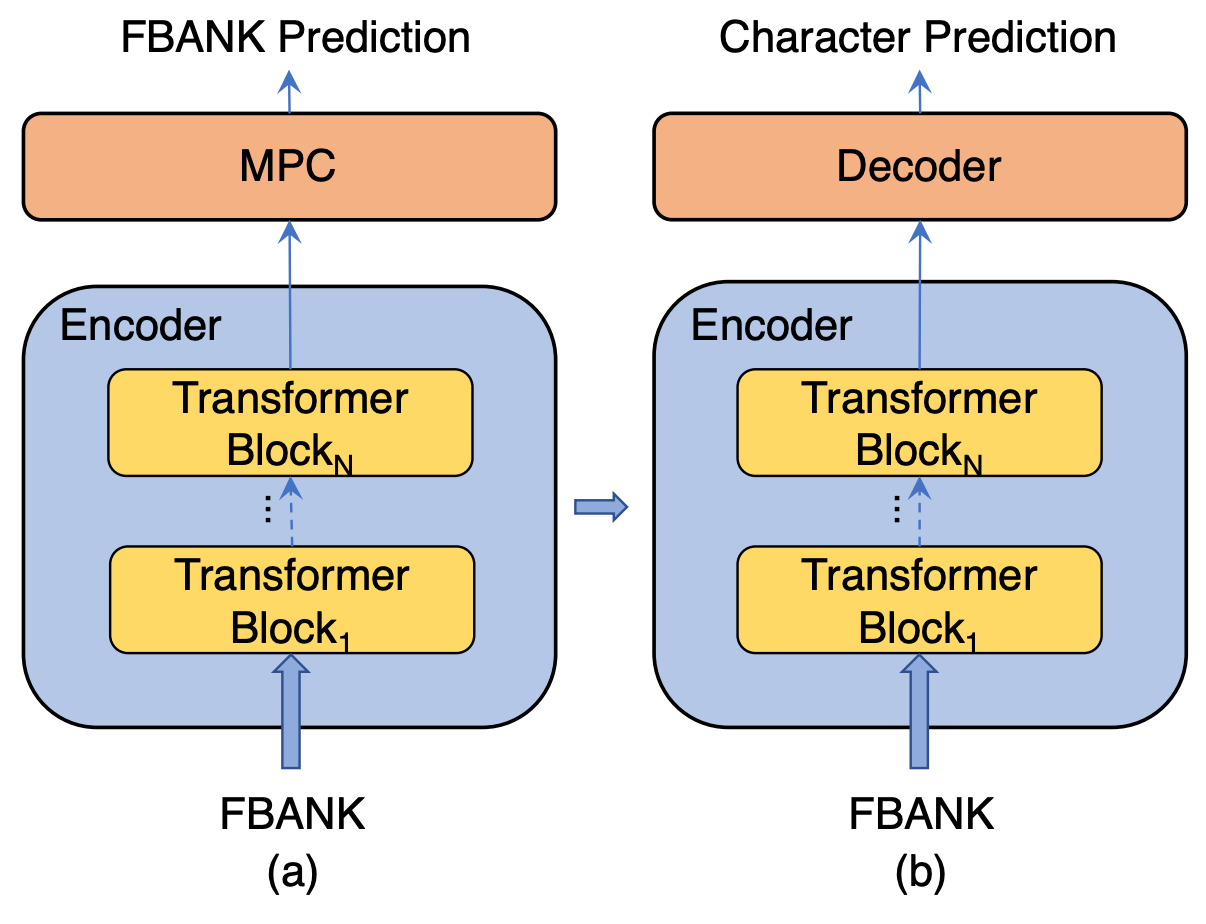
Prior to my current role, I spent six years in industry working on speech processing, where I pioneered self-supervised learning approaches for speech (like masked predictive coding [7] and Speech SimCLR [8]) and was among the first to deploy end-to-end ASR systems at production scale. Following the release of ChatGPT, I recognized the enormous potential of foundation models and wanted to study them deeply without distractions, so I returned to academia to complete my master’s degree at JHU. There, I worked with Professor Daniel Khashabi and Benjamin Van Durme, and also collaborated with Professor Shay Cohen from Edinburgh, Greg Durrett from NYU, and Dawn Song from UC Berkeley on various research projects. Currently, I’m working as an Applied Scientist at Amazon, where I continue to pursue research in foundation models and related areas. I’ve had help from a lot of people throughout my journey, and I believe in giving it back. If I can be of service, feel free to book time on my calendar.
In my free time, I sometimes play Civ 6 or Hearthstone. I also rotate between tennis, badminton, swimming, and bouldering every day—well, more like every three or four days, but who’s counting? Research shows racquet sports can reduce mortality risk by 47% and swimming by 28%—so between all these activities, I’m either achieving immortality or just really bad at math :) There’s actually something puzzle-like about all these activities which probably explains why I enjoy them alongside my research work.
Selected Publications
-
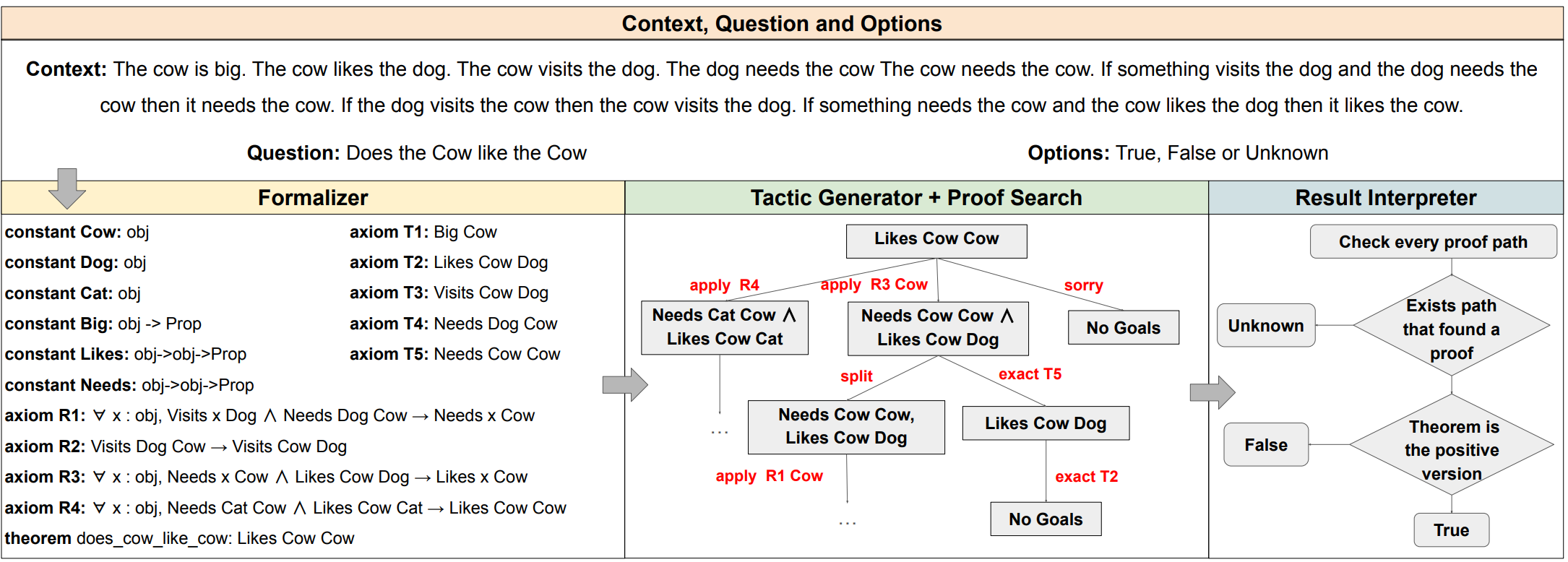 LeanReasoner: Boosting Complex Logical Reasoning with Lean, NAACLIn Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024, Jul 2024
LeanReasoner: Boosting Complex Logical Reasoning with Lean, NAACLIn Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024, Jul 2024

![self-[in]correct.png](/assets/img/publication_preview/self-%5Bin%5Dcorrect.png)